jenkins 部署手册
本文档的作用在于讲解后端项目的持续集成部署方案。基于
jenkins多分支流水线来构建。
多分支流水线介绍
- 提供了一种自动化的方式来构建、测试和部署软件。它可以根据预定义的规则,自动触发构建过程,减少了手动操作的需求,节省了开发人员的时间和精力。
- 允许定义多个不同的阶段和步骤,以适应不同的构建和部署需求。可以根据项目的特定要求,自定义流水线的不同阶段,并在需要时添加或删除步骤。
- 提供了一个可视化的用户界面,可以清楚地展示整个构建和部署过程,以及每个阶段和步骤的执行状态。这使得开发团队可以更好地跟踪和监控整个流程的进展和结果。
- 记录了每次构建的详细信息,包括构建的结果、所用的代码版本、构建的时间等。这些信息可以帮助开发团队追溯问题,分析失败的构建,并作出相应的调整和改进。
- 可以与各种不同的插件和工具集成,以满足复杂的构建和部署需求。通过与其他工具的集成,可以进一步扩展和定制流水线的功能和能力。
环境准备
- jenkins docker 安装
docker pull jenkinsci/blueoceandocker run -it --name jenkins -p 9090:8080 -p 60000:50000 -v jenkins-data:/var/jenkins_home -v /data/web-data/docker.sock:/var/run/docker.sock jenkinsci/blueocean默认安装了Blue Ocean插件
- 插件安装
- Extended Choice Parameter Plug-In
- SSH-Agent
- Maven Integration plugin 使用 maven 构建时需要
- Input-Step
快速创建一个多分支流水线任务
在使用jenkins前,需要安装环境准备阶段提到的插件。接下来我们先创建一个多分支流水线任务。

参照下图进行配置
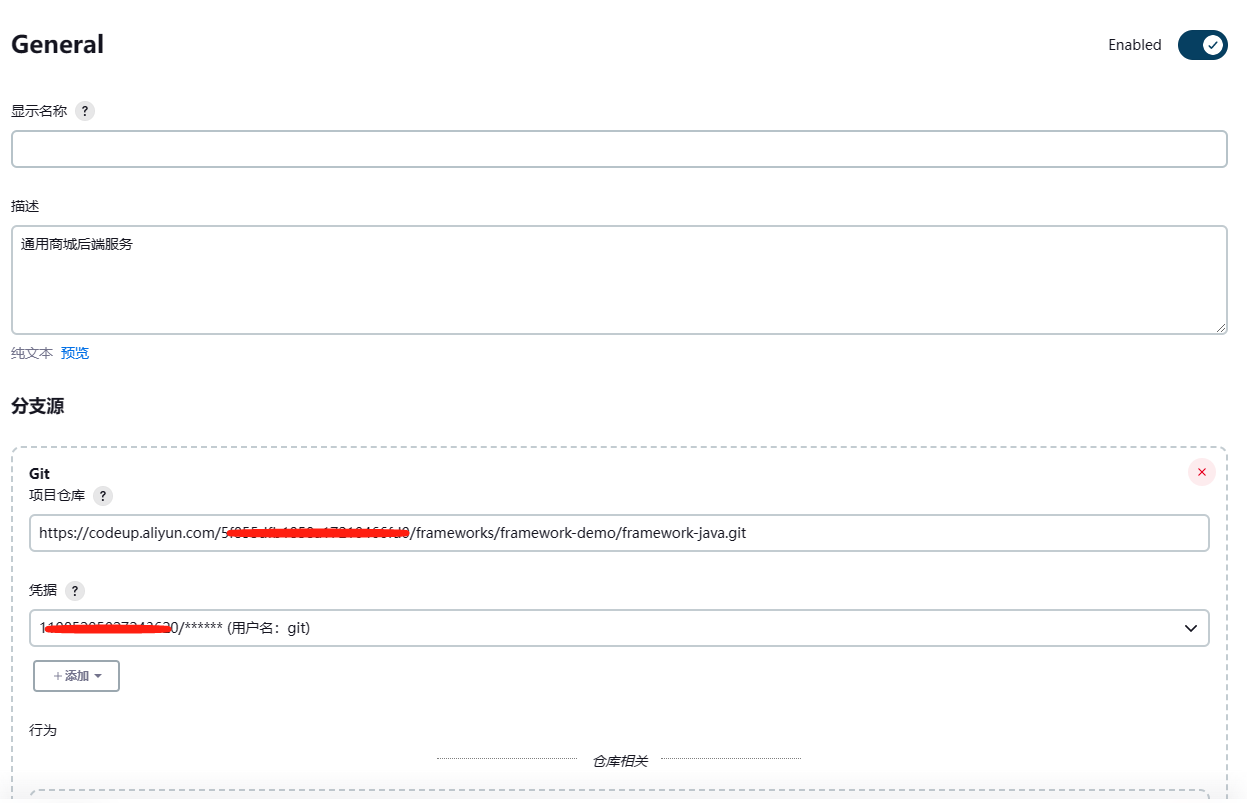
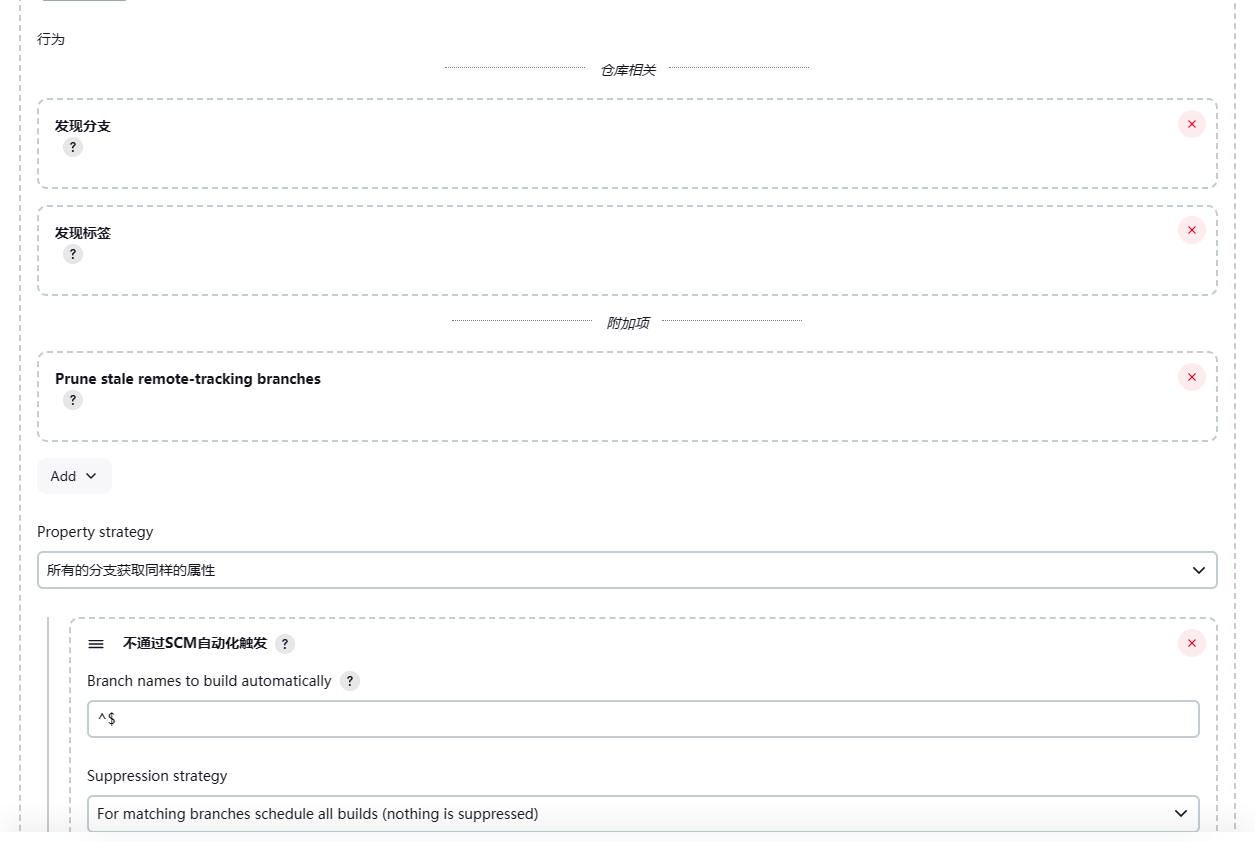
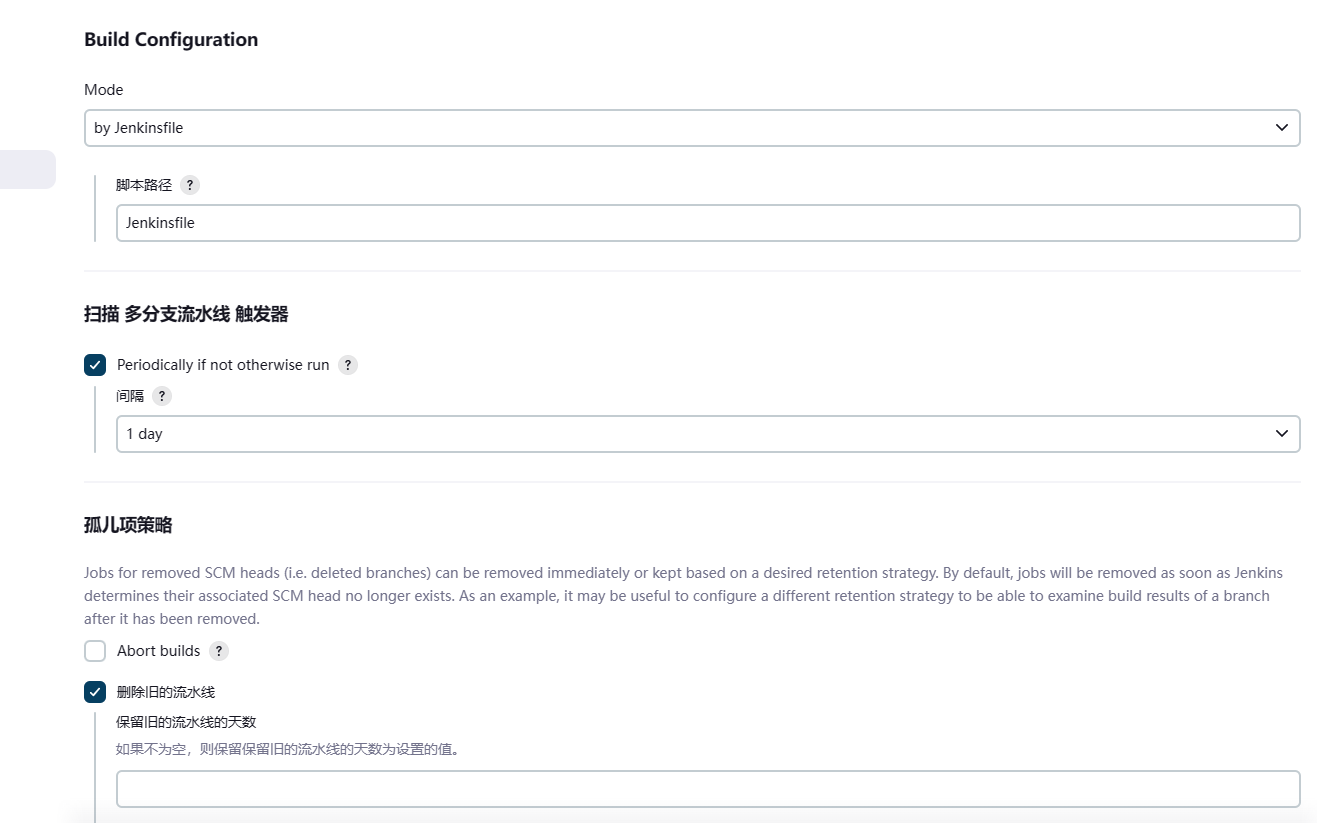
这样配置完就创建了一个流水线任务。
写在前面
接下来重点讲下如何使用jenkins流水线来构建后端Java服务。这里以基础商城为例。先来看几张效果图: 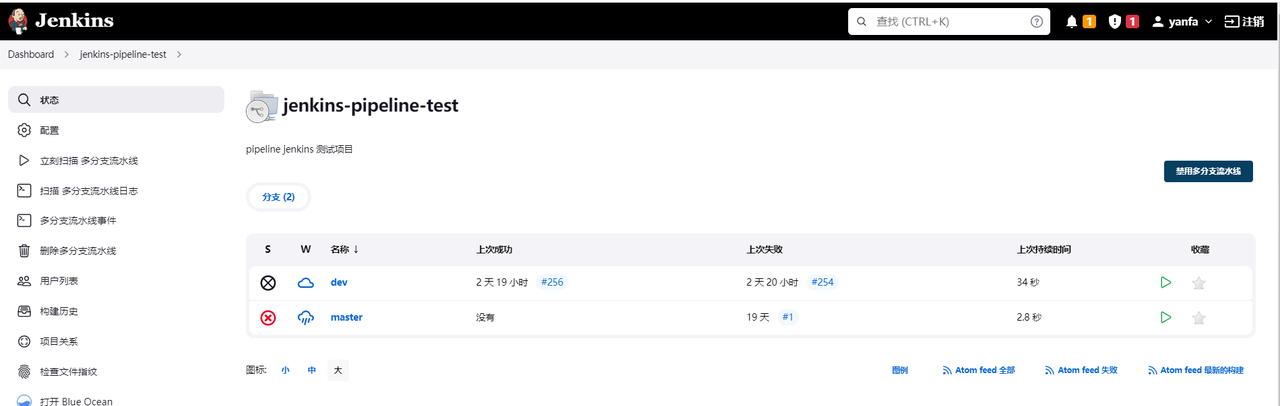
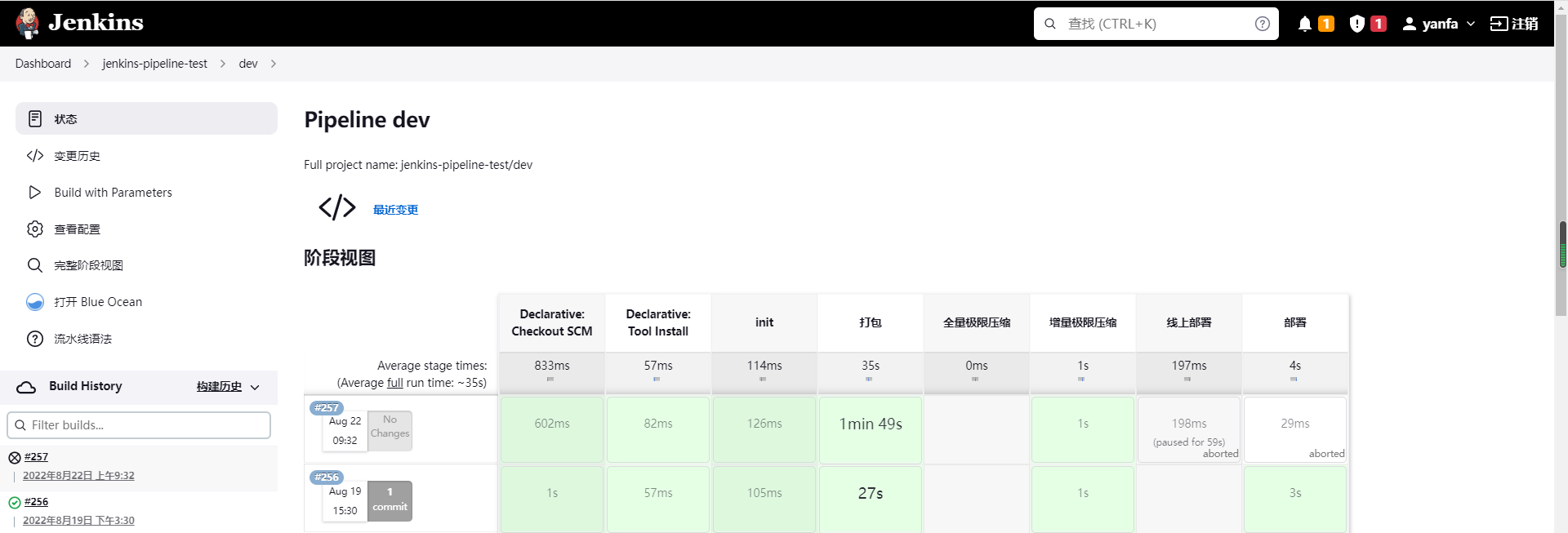 从图中可以看到,我们只要配置了
从图中可以看到,我们只要配置了git,jenkins便能抓取到对应的分支,点击具体分支又能看到流水线的步骤,这又是怎么做到的呢?它是通过下面的文件来生效的:
Jenkinsfile 文件
pipeline {
agent any
tools {
maven '3.6.3'
}
environment {
_version = "1.0"
}
parameters {
extendedChoice(
name: 'mode',
description: '请选择部署方式,deploy 部署,restart 重启,stop 停止',
type: 'PT_SINGLE_SELECT',
value: "${modeList}"
)
extendedChoice(
name: 'env',
description: '请选择一个环境进行部署',
type: 'PT_SINGLE_SELECT',
value: "${envList}"
)
extendedChoice(
name: 'moduleName',
description: '请选择一个模块进行构建,按住 ctrl 可多选',
type: 'PT_MULTI_SELECT',
value: "${projectList}"
)
booleanParam(name: 'cleanMaven', defaultValue: "${cleanMaven}", description: '是否需要让 maven 每次都 clean 工程?')
booleanParam(name: 'forceUpdateMaven', defaultValue: "${forceUpdateMaven}", description: '是否需要让 maven 强制更新拉取最新 jar?')
booleanParam(name: 'offlineMaven', defaultValue: "${offlineMaven}", description: '是否需要让 maven 离线构建?')
string(
description: '请填写 jdk 启动参数',
name: 'jdkArgs',
defaultValue: "${jdkArgs}"
)
string(
description: '请填写 spring 启动参数,例如 --spring.profiles.active=dev',
name: 'springArgs',
defaultValue: "${springArgs}"
)
string(
description: '请填写 nohup 部署参数,当前只支持指定日志输出目录,默认为 /dev/null。\n 但是请注意,指定了输出目录后,Jenkins 发布成功后会出现无法退出的情况,该参数请在排查问题时指定',
name: 'nohupArgs',
defaultValue: "${nohupArgs}"
)
booleanParam(name: 'isAll', defaultValue: "${isAll}", description: '是否需要全量发布?第一次发布请选择全量')
text(name: 'includeJar', defaultValue: "${includeJar}", description: '增量发布要包含的 jar 包')
}
stages {
stage('init') {
steps {
echo "当前版本:${_version}"
script {
currentSelectModuleNames = params.moduleName.split(',').collect { it }
}
}
}
stage('build') {
when {
expression { params.mode == "deploy" }
}
steps {
script {
echo "开始打包${params.moduleName}模块"
def forceUpdate = params.forceUpdateMaven ? "-U" : ""
def offline = params.offlineMaven ? "-o" : ""
def clean = params.cleanMaven ? "clean" : ""
sh "mvn -T 1C ${clean} ${offline} -Dmaven.test.skip=true ${forceUpdate} package -P ${params.env} -am -pl ${params.moduleName}"
echo '打包成功'
}
}
}
stage('zip') {
when {
expression { params.mode == "deploy" }
}
steps {
zipParallel items: currentSelectModuleNames
}
}
stage('线上部署') {
when {
beforeInput true
expression { params.env == "prod" }
}
steps {
timeout(time: 60, unit: 'SECONDS') {
script {
println '等待用户确认,60秒后无确认将自动取消'
def approvalMap = input(
message: "确定要部署到线上环境吗?",
ok: "确定",
id: "${project.id}",
submitter: "yanfa",
submitterParameter: "submitUser"
)
println "输入完成 ${approvalMap}"
}
}
}
}
stage('deploy') {
steps {
deployParallel (items: currentSelectModuleNames, projectName: project.name, projectTargetDir: project.targetDir)
}
}
}
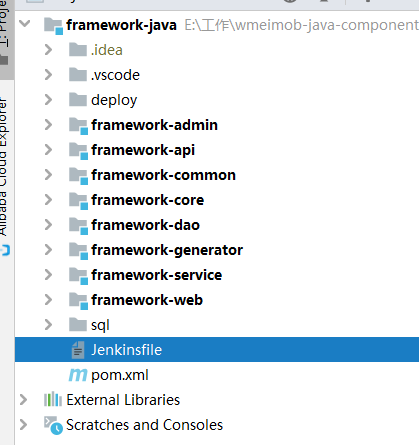
}它的格式就是这样的,没有什么好说的。只能通过官网来看。支持使用groovy语言来做一些更高级的定制。这个文件存在于java项目的根目录之中。如下图:
其中,可以看到parameters指令的作用效果如下图:
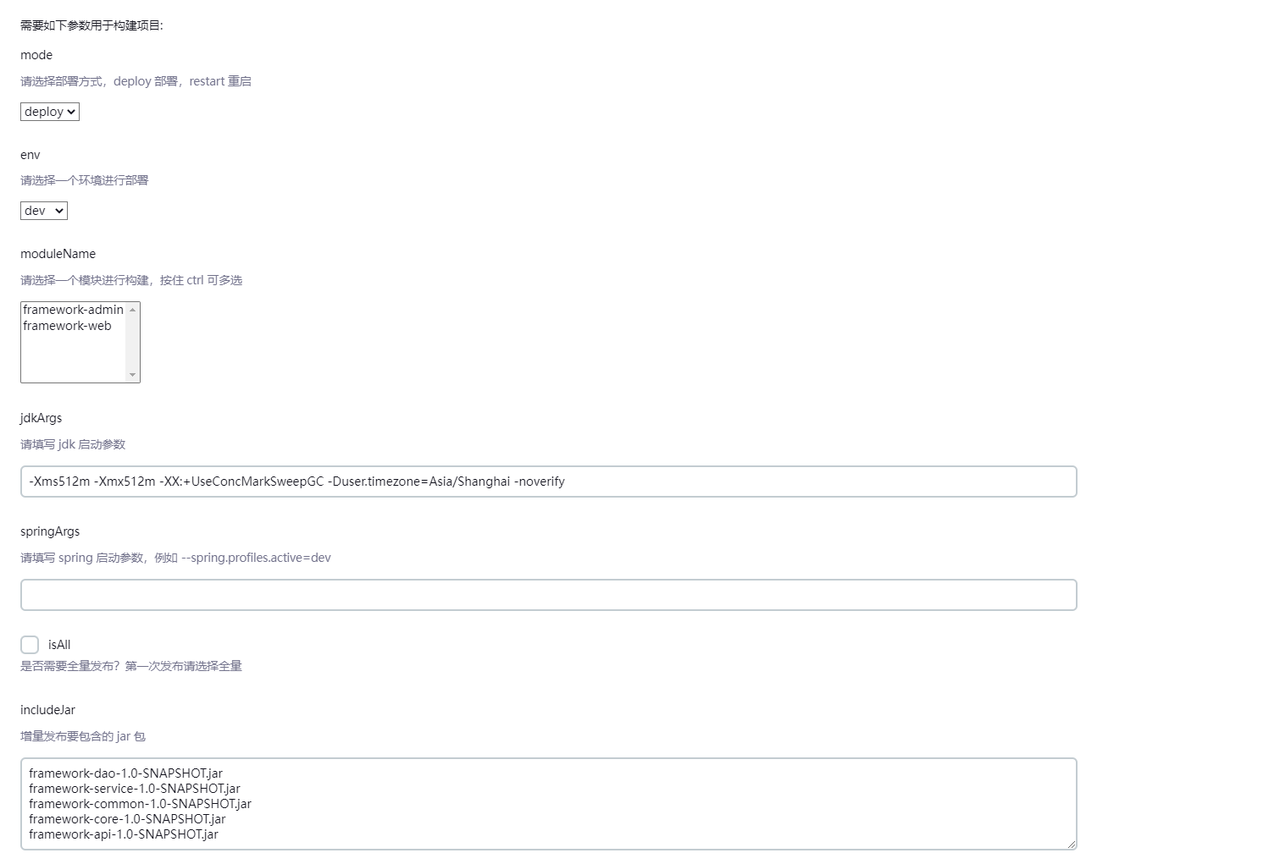
也就是说,通过这个指令我们可以添加更多个性化的参数构建需求。但同时,我们看到上面配置文件中parameters参数节点的value使用了${}变量。那这部分又是怎么生效的呢?是这样的,为了更好的控制节点变量值,这部分配置被提取成一段json。配置如下:
json_str = '''
{
"env": ["dev", "test", "prod"],
"deploy": {
"dev": {
"host": "root@xx.xx.xx.xx",
"credentials": "xxxxxx-2715-4cd0-ada6-693263418623"
},
"test": {
"host": "root@xx.xx.xx.xx",
"credentials": "xxxxxx-2715-4cd0-ada6-693263418623"
},
"prod": {
"host": "root@xx.xx.xx.xx",
"credentials": "xxxxxx-2715-4cd0-ada6-693263418623"
}
},
"mode": ["deploy", "restart", "stop"],
"project": {
"id": "tlDcDhD6gymbjXmp",
"name": "general-mall",
"list": ["framework-admin", "framework-web"],
"targetDir": "/var/workspace/yanfazhongxin/general-mall"
},
"options": {
"maven": {
"forceUpdate": false,
"offline": true,
"clean": false
},
"isAll": false,
"jdkArgs" : "-Xms512m -Xmx512m -XX:+HeapDumpOnOutOfMemoryError -XX:+UseConcMarkSweepGC -Duser.timezone=Asia/Shanghai -noverify",
"springArgs": "",
"nohupArgs": "/dev/null",
"includeJar": "framework-dao-1.0-SNAPSHOT.jar\nframework-service-1.0-SNAPSHOT.jar\nframework-common-1.0-SNAPSHOT.jar\nframework-core-1.0-SNAPSHOT.jar\nframework-api-1.0-SNAPSHOT.jar"
}
}
'''通过维护json配置,来达到变更配置的目的。那流水线的步骤又是怎么来的呢?它是通过stage step来展示流水线步骤的,如下:
stages {
stage('init') {
steps {
echo "当前版本:${_version}"
script {
currentSelectModuleNames = params.moduleName.split(',').collect { it }
}
}
}
stage('build') {
when {
expression { params.mode == "deploy" }
}
steps {
script {
echo "开始打包${params.moduleName}模块"
def forceUpdate = params.forceUpdateMaven ? "-U" : ""
def offline = params.offlineMaven ? "-o" : ""
def clean = params.cleanMaven ? "clean" : ""
sh "mvn -T 1C ${clean} ${offline} -Dmaven.test.skip=true ${forceUpdate} package -P ${params.env} -am -pl ${params.moduleName}"
echo '打包成功'
}
}
}
stage('zip') {
when {
expression { params.mode == "deploy" }
}
steps {
zipParallel items: currentSelectModuleNames
}
}
stage('线上部署') {
when {
beforeInput true
expression { params.env == "prod" }
}
steps {
timeout(time: 60, unit: 'SECONDS') {
script {
println '等待用户确认,60秒后无确认将自动取消'
def approvalMap = input(
message: "确定要部署到线上环境吗?",
ok: "确定",
id: "${project.id}",
submitter: "yanfa",
submitterParameter: "submitUser"
)
println "输入完成 ${approvalMap}"
}
}
}
}
stage('deploy') {
steps {
deployParallel (items: currentSelectModuleNames, projectName: project.name, projectTargetDir: project.targetDir)
}
}
}效果如下图:

这其中,比较重要的是,要怎么获取用户选择的参数呢?通过如下的方式来获取:
${params.xxx} --xxx 为 parameters 中控件的 name部署方式
"mode": ["deploy", "restart", "stop"]- deploy 每次都会根据选择的环境和应用启动参数来执行部署,默认:deploy
- restart 仅仅只是根据选择的环境和应用启动参数来重启应用
- stop 仅仅只是杀掉进程
最终的效果是这样的:

环境定义
在 json 配置里存在着如下的配置:
"env": ["dev", "test", "prod"]最终的效果是这样的:

所以,当你需要在定义一个新的环境的时候,可以去调整对应的json配置节点。
编译
编译环节没有什么好介绍的了。根据选择的模块来构建。如下:
stage('build') {
when {
expression { params.mode == "deploy" }
}
steps {
script {
echo "开始打包${params.moduleName}模块"
def forceUpdate = params.forceUpdateMaven ? "-U" : ""
def offline = params.offlineMaven ? "-o" : ""
def clean = params.cleanMaven ? "clean" : ""
sh "mvn -T 1C ${clean} ${offline} -Dmaven.test.skip=true ${forceUpdate} package -P ${params.env} -am -pl ${params.moduleName}"
echo '打包成功'
}
}
}重点说明下,这里提供了三个参数来控制 maven 的编译。它们分别是:
"options": {
"maven": {
"forceUpdate": false,
"offline": true,
"clean": false
}
}- forceUpdate 是否需要让 maven 强制更新拉取最新 jar
- offline 是否需要让 maven 离线构建
- clean 是否需要让 maven 每次都 clean 工程
通过这三个参数的组合,能大大的提高编译的速度。
效果如下图:

可以看到在优化前,常规构建的时间需要近50秒,极端的需要1分多种,偶尔快的话,可以36秒。优化后,可以看到,8秒便构建成功了。
全量压缩与增量压缩
全量与增量的效果如下图:

它是通过下面json配置段来控制的:
"options": {
"isAll": false
}从图中的描述可以看出,第一次发布需要使用全量。后续版本发布,没有特殊引入包的情况下,均可以使用增量发布(默认增量)。因为增量发布比较快速,只需要几秒钟就可以发布成功。全量的话,打完包超过100M。发布速度可想而知快不了。那增量又该怎么配置呢?它也是通过如下的json配置段来控制的:
"options": {
"includeJar": "framework-dao-1.0-SNAPSHOT.jar\nframework-service-1.0-SNAPSHOT.jar\nframework-common-1.0-SNAPSHOT.jar\nframework-core-1.0-SNAPSHOT.jar\nframework-api-1.0-SNAPSHOT.jar"
}实际上这里配置的是jar的名称,用\n换行符来分隔。也就是当你引入新的jar时,如果你能确定变更的jar,便可以在发布的时候指定,如果不确定,便就是发布全量。 效果如下图:

发布
发布到底是将服务部署到哪里去呢?首先在如下json配置段:
"deploy": {
"dev": {
"host": "root@xx.xx.xx.xx",
"credentials": "98ea5f9a-2715-4cd0-ada6-693263418623"
},
"test": {
"host": "root@xx.xx.xx.xx",
"credentials": "98ea5f9a-2715-4cd0-ada6-693263418623"
},
"prod": {
"host": "root@xx.xx.xx.xx",
"credentials": "6fa9cd30-e20a-4044-9b7f-b81eee47408f"
}
}这里定义了与环境相匹配的部署信息。其中:
- host 部署的主机账号和ip
- credentials 连接服务器的凭据ID。那这个信息要从哪里来呢? 一开始我们在环境准备阶段安装了ssh-agent插件,后续会通过这个插件来连接远端服务器,然后做发布。而他们之间的通信为了安全,我们选择公私钥的方式进行连接。首先在
jenkins部署的机子上执行如下代码:
su -s /bin/bash jenkins
ssh-keygen -t rsa -b 4096
cd /root/.ssh
ls最终会生成 ssh private key、public key 。id_rsa为 private key,id_rsa.pub为public key。 然后再执行如下代码:
ssh-copy-id -i ~/.ssh/id_rsa.pub xx@x.x.x.x🎉 格式一般为 root@192.168.0.1 将公钥分发到指定的账号主机上。这样完了后,便可以使用ssh-agent免密登录对应的主机。这样完了后,还需要再jenkins上添加对应的凭证。如下图:

类型选择 ssh username with private key。填写主机对应的 username,再将前面生成id_rsa内容复制到 private key 处。保存后ID的值便是我们前面说的"credentials"连接服务器的凭据ID!!! 这些都有了后,便可以根据选择的环境发布到对应的主机了。而项目的相关配置在如下json配置段:
"project": {
"id": "tlDcDhD6gymbjXmp",
"name": "general-mall",
"list": ["framework-admin", "framework-web"],
"targetDir": "/var/workspace/yanfazhongxin/general-mall"
}- name 项目名称
- list 项目列表
- targetDir 项目部署路径
而比较特别的是,当在部署prod环境时,会提供一个交互式应答,发布者必须点击确认才能继续发布,如下图:

服务部署后的服务名称为如下三个元素的组合:
${projectName}-${moduleName}-${env}例如:general-mall-framework-web-test
代码漏洞扫描
通过集成murphysec插件可以很方便对项目的代码进行漏洞扫描。首先登录到墨菲控制台,如图复制访问令牌。  接着进入 cli 集成界面。复制linux下的命令行。直接在jenkins宿主机安装。
接着进入 cli 集成界面。复制linux下的命令行。直接在jenkins宿主机安装。
wget -q https://s.murphysec.com/release/install.sh -O - | /bin/bash安装完后执行。
murphysec auth login根据提示粘贴访问令牌。 如果不和jenkins进行集成的话,到这里就安装完了。可以体验下如下命令:
murphysec scan 项目路径关键步骤:先执行下命令
whereis murphysec默认安装在
/usr/local/bin/murphysec调整下目录路径
mv /usr/local/bin/murphysec /usr/bin/murphysec由于jenkins是通过docker安装的。可以进行这样操作:
docker cp /usr/bin/murphysec jenkins:/root/murphysec进入 docker 容器
docker exec -it jenkins bash为文件赋予权限
cd /root
chmod +x murphysec配置完成后。可以在jenkins里配置下访问令牌的存储。 找到系统管理 -> manager credentials -> 添加凭证 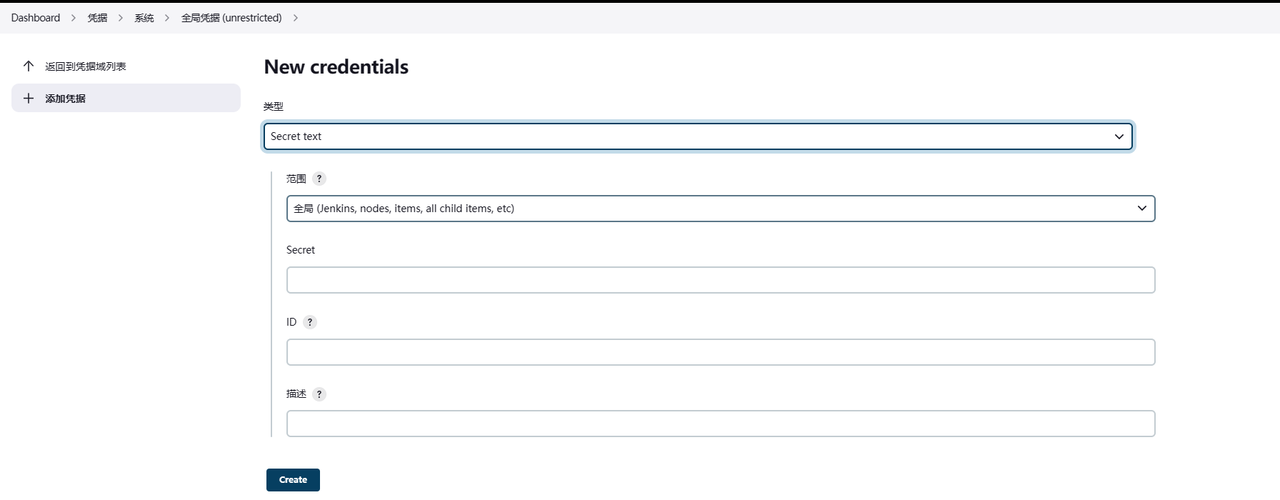 将访问令牌粘贴到这里。 最终效果:
将访问令牌粘贴到这里。 最终效果:  最后 jenkinsFile 文件里增加一个流水线即可
最后 jenkinsFile 文件里增加一个流水线即可
stage("漏洞扫描") {
when {
expression { params.mode == "security check" }
}
environment {
API_TOKEN = credentials('murphysec-token')
}
steps {
sh '''
murphysec scan .
'''
}
}其他
"options": {
"isAll": false,
"jdkArgs" : "-Xms512m -Xmx512m -XX:+UseConcMarkSweepGC -Duser.timezone=Asia/Shanghai -noverify",
"springArgs": "",
"nohupArgs": "/dev/null",
"includeJar": "framework-dao-1.0-SNAPSHOT.jar\nframework-service-1.0-SNAPSHOT.jar\nframework-common-1.0-SNAPSHOT.jar\nframework-core-1.0-SNAPSHOT.jar\nframework-api-1.0-SNAPSHOT.jar"
}- isAll 是否全量
- jdkArgs 部署或重启时可以指定 jdk 运行参数
- springArgs 部署或重启时可以指定 spring 启动参数
- nohupArgs 部署时排查错误,可临时指定为某个路径地址
- includeJar 增量发布所包含的jar
并行构建
并行构建到底并行构建什么呢?我理解的话,是打包阶段,部署阶段能并行就ok了。那我们应该要怎么改呢?先来看下现在的效果图:
- 需要将模块由下拉单选改成可以多选 只需要 PT_SINGLE_SELECT 改成 PT_MULTI_SELECT 即可
- 需要处理选取的模块
- 流水线打包编译阶段需要支持并行操作
def currentSelectModuleNames = params.moduleName.split(',').collect { it }定义一个变量来表示当前选择的模块。 Maven 编译命令是支持多模块构建的:
mvn clean -Dmaven.test.skip=true package -P ${params.env} -am -pl ${params.moduleName}接下来部署阶段只要这样做就行了:
stage('deploy') {
steps {
deployParallel (items: currentSelectModuleNames, projectName: project.name, projectTargetDir: project.targetDir)
}
}
void deployParallel(args) {
def deploy = getConfig("deploy")
def deployEnv = deploy[params.env]
parallel args.items.collectEntries { name -> [ "${name}": {
stage("deploy ${name}") {
echo "开始部署${name}模块,${params.env}环境"
remoteDeploy(deployEnv.host, deployEnv.credentials, args.projectName, args.projectTargetDir, name)
echo "部署成功"
}
}]
}
}增加parallel关键字即可。最后的效果图如下:


常见问题
jenkins运行后程序没有启动 解决方法:调整 nohup 命令中的 /dev/null 为某个路径地址,再次发布。查看该文件内容,如果错误内容为 nohup: failed to run command 'java': No such file or directory。则可以运行如下命令:
# 找到安装位置
find / -name "java"
# 切换到该目录
cd /usr/bin
# 建立软链接,替换目录为上面找到的目录
ln -s /usr/local/jdk1.8.0_311/bin/java /usr/bin/java重新执行完后,可重新在发布。
jenkins发布后长时间没有退出,一直 loading 解决方法:查看 nohup 命令中 /dev/null 是否修改为其他路径了,因为你一旦改成其他路径后,jenkins发布完成后会出现无法正确退出的情况,这是一个 bug。目前只能在调整成 /dev/null 规避这个问题。