k8s
本小节将会包含
测试与线上均为一套环境,微服务涉及的组件均与命名空间进行区分。一般的分为 test,prod,public 三个命名空间。其中 public 在镜像服务中表示公共镜像。
容器镜像介绍
通常在客户购买该服务后,我们需要先创建出 test,prod,public 三个命名空间。而后获取访问凭证,设置密码。对于 java 应用来说,需要导入基础 jdk 镜像。参考如下命令:
docker tag openjdk:8-jdk-alpine xxx/xxx-public/openjdk:8-jdk-alpine
docker push xxx/xxx-public/openjdk:8-jdk-alpine不导入的话,可以直接使用公司公共镜像。
registry.cn-hangzhou.aliyuncs.com/wmeimob/wmeimob:openjdk-8-jdk-alpine对于阿里云企业版来说,镜像可公网进行推送,内网进行拉取。通过以下方法可以达到此效果,
- 内网拉取可在仓库管理 => 访问控制 => 专有网络中进行添加,首次添加页面会进行引导添加云解析
private zone。开通后即可得到内网镜像域名,后续 pod 拉取镜像就可以使用此域名。 - 公网推送需要开通公网入口,同时需要设置公网 ip 白名单,如果是用云效流水线的需要将其 ip 段设置进去。
如下是云效的 ip 段,点此了解更多
47.93.89.246/32
47.94.150.17/32
112.126.70.240/32
123.56.255.38/32
47.94.150.88/32为了比较快速的拉取 pod 中的镜像,可以实现免密拉取。个人版无法使用免密,也无法使用内网地址。
- 阿里云
应用市场安装插件aliyun-acr-credential-helper。在 pod yaml 增加如下配置:
imagePullSecrets: #阿里云镜像配置拉取密钥
- name: acr-credential-secret-aggregation个人版不要安装,以防出现配置好的 secret 被覆盖的风险。
- 腾讯云
在 TKE 集群“组件管理”中安装 TCR 插件,并在 “TCR 组件参数设置”窗口中勾选"启用内网解析功能"。该插件可自动为集群内节点配置关联 TCR 实例的内网解析,可实现内网免密拉取实例内镜像。插件安装完成后,集群将具备内网免密拉取该关联实例内镜像的能力,无需额外配置。
当这些配置好了,我们可以准备一个 dockerfile 文件,如下:
FROM registry.cn-hangzhou.aliyuncs.com/wmeimob/wmeimob:openjdk-8-jdk-alpine
#构建参数
ARG EXPOSE_PORT=18080
#设置工作目录
RUN mkdir -p /app
WORKDIR /app
## 将后端项目的 Jar 文件,复制到镜像中
COPY ./target/gateway.jar app.jar
## 设置 TZ 时区
## 设置 JAVA_OPTS 环境变量,可通过 docker run -e "JAVA_OPTS=" 进行覆盖
ENV TZ=Asia/Shanghai JAVA_OPTS="-Dfile.encoding=UTF8 -Duser.timezone=GMT+08 -Xms512m -Xmx512m"
# 指定于外界交互的端口
EXPOSE $EXPOSE_PORT
RUN echo "java -jar \${JAVA_OPTS} app.jar" > start.sh \
&& chmod 777 start.sh
ENTRYPOINT ./start.sh通过 docker push 命令进行推送即可。当镜像产生后,该如何部署呢?通过云平台提供的 UI 控制台进行创建,还是其他方式呢?为了达到快速部署及标准化部署的目的,提供了一套标准部署模板脚本,其中主要变量均提取出来了。
一键生成java部署yaml脚本
部署脚本提供哪些模板呢?如下:
deployment&service
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${APP_NAME}
namespace: ${APP_NAMESPACE}
annotations:
description: ${APP_DESCRIPTION}
labels:
app: ${APP_NAME}
spec:
selector:
matchLabels:
app: ${APP_NAME}
replicas: ${REPLICAS} # Pod副本数
strategy:
type: RollingUpdate # 滚动更新策略
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
template:
metadata:
name: ${APP_NAME}
labels:
app: ${APP_NAME}
armsPilotAutoEnable: "off" #开启接入阿里云 arms
armsPilotCreateAppName: "${APP_NAME}-${APP_NAMESPACE}"
armsSecAutoEnable: "off" #如果需要接入应用安全,则需要配置此参数。
annotations:
timestamp: ${TIMESTAMP}
prometheus.io/port: "50000" # 不能动态赋值
prometheus.io/path: /actuator/prometheus
prometheus.io/scrape: "true" # 基于pod的服务发现
spec:
affinity: # 设置调度策略,采取多主机/多可用区部署
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- ${APP_NAME}
topologyKey: "kubernetes.io/hostname" # 多可用区为"topology.kubernetes.io/zone"
dnsPolicy: ClusterFirst
restartPolicy: Always
terminationGracePeriodSeconds: 90 # 默认30s,优雅终止宽限期
containers:
- env:
- name: JAVA_OPTS
valueFrom:
configMapKeyRef:
key: JAVA_OPTS
name: java-opts
optional: false
- name: aliyun_logs_${APP_NAME}-${APP_NAMESPACE} #阿里云特有 log
value: stdout
- name: aliyun_logs_logtag-${APP_LOG_TAG}_tags
value: app=${APP_NAME}-${APP_NAMESPACE}
image: ${IMAGE_URL}
imagePullPolicy: Always
startupProbe: # 存活探针
httpGet:
path: /actuator/health/liveness
port: management-port
scheme: HTTP
initialDelaySeconds: ${INITIAL_DELAY_SECONDS} # 延迟加载时间
periodSeconds: 10 # 重试时间间隔
timeoutSeconds: 10 # 超时时间设置
successThreshold: 1 # 健康阈值
failureThreshold: 20 # 不健康阈值
livenessProbe: # 存活探针
httpGet:
path: /actuator/health/liveness
port: management-port
scheme: HTTP
initialDelaySeconds: 30 # 延迟加载时间
periodSeconds: 10 # 重试时间间隔
timeoutSeconds: 1 # 超时时间设置
successThreshold: 1 # 健康阈值
failureThreshold: 6 # 不健康阈值
name: ${APP_NAME}
ports:
- containerPort: ${APP_PORT}
protocol: TCP
- name: management-port
containerPort: 50000 # 应用管理端口
protocol: TCP
readinessProbe: # 就绪探针
httpGet:
path: /actuator/health/readiness
port: management-port
scheme: HTTP
initialDelaySeconds: 35 # 延迟加载时间
periodSeconds: 10 # 重试时间间隔
timeoutSeconds: 1 # 超时时间设置
successThreshold: 1 # 健康阈值
failureThreshold: 3 # 不健康阈值
resources: # 容器资源管理
limits: # 资源限制(监控使用情况)
cpu: 0.5
memory: 1Gi
requests: # 最小可用资源(灵活调度)
cpu: 0.1
memory: 512Mi
<#if aliyun>
imagePullSecrets: #阿里云镜像配置拉取密钥
- name: acr-credential-secret-aggregation
</#if>apiVersion: v1
kind: Service
metadata:
labels:
app: ${APP_NAME}
name: ${APP_NAME}
namespace: ${APP_NAMESPACE}
spec:
ports:
- port: ${APP_PORT}
protocol: TCP
targetPort: ${APP_PORT}
selector:
app: ${APP_NAME}
sessionAffinity: None
type: ClusterIP我们来导读一下这个模板到底做了哪些东西?
- 声明基本的元数据名称
- 声明了容器的使用资源(默认内存512m,最大1g,cpu 0.1~0.5)
- 声明了 pod 反亲和性,不让其调度到同一个节点上
- 自动接入阿里云 arms(apm)调用链监控系统(默认关闭, on 开启),开启后需要在 ACK 集群组件管理中安装“ack-onepilot”插件
- 自动引入 JVM 参数 JAVA_OPTS 的引用(configmap)中定义
- 自动接入阿里云日志平台
- 定义了三个 k8s 探针用于健康检查(程序需要接入 actuator health,默认端口50000),INITIAL_DELAY_SECONDS 变量,gateway 建议 60,业务服务建议 120
- 定义了滚动更新策略(模板默认生成单 pod,maxSurge 默认为1,表示可超过现有副本数+1个,maxUnavailable 默认为0,表示 pod 不可用为0)即单 pod 必须等新 pod 就绪,老 pod 才能终止
- 根据云环境自动配置镜像拉取策略(镜像章节介绍过免密拉取)
- 定义了访问 pod 的方式(即 service 通过 ClusterIP 访问,注意,所有 pod 都不对外,只在负载均衡层暴露 gateway)
configmap
apiVersion: v1
data:
JAVA_OPTS: "
-XX:NewRatio=2
-XX:SurvivorRatio=8
-XX:InitialRAMPercentage=75.0
-XX:MaxRAMPercentage=75.0
-XX:MinRAMPercentage=75.0
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintTenuringDistribution
-XX:+PrintHeapAtGC
-XX:+PrintReferenceGC
-XX:+PrintGCApplicationStoppedTime
-Xloggc:/app/logs/gc%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=15
-XX:GCLogFileSize=50M
-Xss256K
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-Dfile.encoding=UTF8
-Duser.timezone=Asia/Shanghai
-Ddubbo.application.logger=slf4j
-noverify
"
kind: ConfigMap
metadata:
name: java-opts
namespace: ${APP_NAMESPACE}我们来导读一下这个模板到底做了哪些东西?
- 声明了 jvm 启动基本参数
这里并没有声明堆大小,直接用默认的吗?并不是。这是因为在容器环境下,并不能直接这样写死 -Xms512m -Xmx512m,为什么呢?这是因为容器资源是弹性,当资源给到1g,2g,4g时,java 应用是弹性变化的,所以在上面的声明中有三个重要参数:
-XX:InitialRAMPercentage=75.0
-XX:MaxRAMPercentage=75.0
-XX:MinRAMPercentage=75.0它表示使用分配资源的百分比,即使用 75% 的内存资源。
同时这里定义了参数:
-XX:NewRatio=2
-XX:SurvivorRatio=8NewRatio 表示新生代与老年化的比例。为2时,也就是说,如果堆内存总大小为3G,新生代占1G,老年代占2G。 SurvivorRatio 是用于调整新生代区的空间比例的参数,默认为8。
ingress-nginx-ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
<#if aliyun == false>
kubernetes.io/ingress.class: ${APP_NAMESPACE}
kubernetes.io/ingress.rule-mix: "true"
</#if>
nginx.ingress.kubernetes.io/cors-allow-headers: DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization
nginx.ingress.kubernetes.io/cors-allow-methods: GET, PUT, DELETE, POST, OPTIONS
nginx.ingress.kubernetes.io/cors-allow-origin: '*' # localhost 必须连端口也一起指定 http://localhost:9090
nginx.ingress.kubernetes.io/cors-expose-headers: Content-Length,Content-Range,Content-Disposition
nginx.ingress.kubernetes.io/enable-cors: "true"
nginx.ingress.kubernetes.io/configuration-snippet: >
more_set_headers "cache-Control: no-cache, no-store"; if ($request_uri ~*
\.(?:ico|css|js|gif|jpg|jpeg|png|svg|woff2|woff|ttf|eo|mp3|glb)($|\?.*)) {
more_set_headers "cache-control: public, max-age=2592000";
}
name: ingress
namespace: ${APP_NAMESPACE}
<#if aliyun>
labels:
ingress-controller: nginx
</#if>
spec:
<#if aliyun>
ingressClassName: nginx
</#if>
rules:
- host: ${EXTEND_APP_HOST}
http:
paths:
- backend:
service:
name: gateway
port:
number: ${EXTEND_APP_PORT}
path: /
pathType: ImplementationSpecific
- backend:
service:
name: xxl-job-admin
port:
number: 8080
path: /job-admin
pathType: ImplementationSpecificapiVersion: cloud.tencent.com/v1alpha1
kind: NginxIngress
metadata:
name: nginxIngress
spec:
ingressClass: nginxIngress
service:
annotation:
service.kubernetes.io/qcloud-share-existed-lb: "true"
service.kubernetes.io/service.extensiveParameters: '{"AddressIPVersion":"IPV4"}'
service.kubernetes.io/tke-existed-lbid: ${APP_LB_ID}
tke.cloud.tencent.com/networks: tke-route-eni
tke.cloud.tencent.com/vpc-ip-claim-delete-policy: Never
directAccess: true
type: LoadBalancer
watchNamespace: ${APP_NAMESPACE}
workLoad:
hpa:
enable: true
maxReplicas: 2
metrics:
- pods:
metricName: k8s_pod_rate_cpu_core_used_limit
targetAverageValue: "80"
type: Pods
minReplicas: 1
template:
affinity: { }
container:
image: ccr.ccs.tencentyun.com/tkeimages/nginx-ingress-controller:v1.9.5
resources:
limits:
cpu: "0.5"
memory: 1024Mi
requests:
cpu: "0.25"
memory: 512Mi
type: deployment我们来导读一下这个模板到底做了哪些东西?
对于 ingress 来说,定义了:
- 定义了跨域配置
- 其中 cors-expose-headers 中定义了 Content-Disposition 头,这个是用来后端输出 excel 文件流
- 定义了外部访问域名关联的 gateway 端口
- 开启了 gzip
对于 nginx-ingress 来说,阿里云无需定义,因为它会自动帮我们创建出来,如果在购买 ack 集群时,未勾选上 nginx-ingress 组件,则需要在 ACK 集群“组件管理”中安装 Nginx Ingress Controller 插件,安装完后即可生成,可在服务 kube-system 命名空间下找到“nginx-ingress-lb”
而对于腾讯云来说,定义了:
- 引用了定义的 clb id(从负载均衡列表中找到) 值,并与之关联
- 定义了 hpa(最少单 pod,最多两个 pod【当 cpu 利用率(占 limit)80%】时扩容)
- 定义了资源使用情况(默认内存512m,最大1g,cpu 0.25~0.5)
hpa
<#if aliyun>
apiVersion: autoscaling/v2
<#else>
apiVersion: autoscaling/v1
</#if>
kind: HorizontalPodAutoscaler # 弹性伸缩控制器
metadata:
<#if aliyun>
<#else>
annotations:
autoscaling.alpha.kubernetes.io/metrics: '[{"type":"Pods","pods":{"metricName":"k8s_pod_rate_cpu_core_used_limit","targetAverageValue":"80"}},{"type":"Pods","pods":{"metricName":"k8s_pod_rate_mem_no_cache_limit","targetAverageValue":"80"}}]'
</#if>
name: ${APP_NAME}
namespace: ${APP_NAMESPACE}
spec:
behavior:
scaleUp:
stabilizationWindowSeconds: 60 # 等待 60 秒再进行扩容
policies:
- type: Percent
value: 100 # 每次扩容最多增加 100% 的副本数
periodSeconds: 30 # 每 30 秒检查一次扩容
scaleDown:
stabilizationWindowSeconds: 300 # 缩容的稳定窗口为 300 秒
policies:
- type: Percent
value: 50 # 每次缩容最多减少 50% 的副本数
periodSeconds: 60 # 每 60 秒检查一次缩容
maxReplicas: ${MAX_REPLICAS}
<#if aliyun>
metrics:
- external:
metric:
name: arms_app_requests_per_second_${APP_NAME}_${APP_NAMESPACE} # 自定义 hpa 指标
target:
averageValue: 40 # qps 超过40就扩容
type: AverageValue
type: External
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
</#if>
minReplicas: 1 # 缩放范围
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ${APP_NAME}<#list services as service>
- metricsQuery: sum(sum_over_time_lorc(<<.Series>>{service="${service}-${APP_NAMESPACE}",clusterId="${CLUSTER_ID}",serverIp=~".*",callKind=~"http|rpc|custom_entry|server|consumer|schedule",source="apm",<<.LabelMatchers>>}[1m])) or vector(0)
name:
as: "${r'${1}'}_per_second_${service?replace("-","_")}_${APP_NAMESPACE}"
matches: "^(.*)_count_ign_destid_endpoint_ppid_prpc"
resources:
namespaced: false
seriesQuery: arms_app_requests_count_ign_destid_endpoint_ppid_prpc{service="${service}-${APP_NAMESPACE}",clusterId="${CLUSTER_ID}"}
</#list>我们来导读一下这个模板到底做了哪些东西?
- 定义了 cpu 利用率(占 limit)80%,内存 利用率(占 limit)80% 时进行扩容
- 自定义了 qps 指标超过某个阈值时进行扩容,如何使用参考下面高级特性#扩缩容
- 定义了扩容时等待60秒,并按 10% 进行扩容。例如当前副本为10,10%即1,即增加1个。例如出现1.x,则会向上取整。缩容时,设置了等待窗口期,10分钟,每次缩小1个。保住流量平稳
- 定义了 hpa adapter config 模板
这个的好处是什么呢?当某个客户突然要上活动,需要评估流量是否需要加服务器时,我们便可以创建出 hpa,定义 cpu 内存指标或是自定义 qps 指标达到一个阈值时自动触发扩容。但同时我们也要关注扩容的稳定性。主要的目的是快速扩容,缓慢缩容。
xxljob
apiVersion: v1
kind: ConfigMap
metadata:
name: xxl-job-admin-env-configmap
namespace: ${APP_NAMESPACE}
data:
# https://github.com/xuxueli/xxl-job/blob/master/xxl-job-admin/src/main/resources/application.properties
PARAMS: >-
--spring.datasource.url=jdbc:mysql://xx.xx.xx.xx:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
--spring.datasource.username=xx
--spring.datasource.password=xxx
--server.servlet.context-path=/job-admin
--xxl.job.accessToken=xxxxapiVersion: apps/v1
kind: Deployment
metadata:
name: xxl-job-admin
namespace: ${APP_NAMESPACE}
annotations:
description: xxl-job-admin
labels:
app: xxl-job-admin
spec:
replicas: 1
selector:
matchLabels:
app: xxl-job-admin
template:
metadata:
labels:
app: xxl-job-admin
spec:
dnsPolicy: ClusterFirst
restartPolicy: Always
terminationGracePeriodSeconds: 60 # 默认30s,优雅终止宽限期,建议设置为 preStop 的时间再加30秒以上
containers:
- name: xxl-job-admin
image: registry.cn-hangzhou.aliyuncs.com/wmeimob/wmeimob:xxl-job-admin-2.4.1
imagePullPolicy: Always # 优先使用本地镜像
lifecycle:
preStop:
exec:
command:
- sleep 30 #休眠30s,使 Pod 收到 SIGTERM 时 sleep 一段时间而不是立刻停止工作,从而确保从云负载转发的流量还可以继续被 Pod 处理
ports:
- containerPort: 8080
resources: # 容器资源管理
limits: # 资源限制(监控使用情况)
cpu: 2
memory: 1Gi
requests: # 最小可用资源(灵活调度)
cpu: 2
memory: 1Gi
env:
- name: PARAMS
valueFrom:
configMapKeyRef:
name: xxl-job-admin-env-configmap
key: PARAMS
<#if aliyun>
imagePullSecrets: #阿里云镜像配置拉取密钥
- name: acr-credential-secret-aggregation
</#if>apiVersion: v1
kind: Service
metadata:
name: xxl-job-admin
labels:
app: xxl-job-admin
namespace: ${APP_NAMESPACE}
spec:
type: ClusterIP
ports:
- port: 8080
protocol: TCP
targetPort: 8080
sessionAffinity: None
selector:
app: xxl-job-admin#
# XXL-JOB v2.4.2-SNAPSHOT
# Copyright (c) 2015-present, xuxueli.
# https://github.com/xuxueli/xxl-job/blob/master/doc/db/tables_xxl_job.sql
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;我们来导读一下这个模板到底做了哪些东西?
- 将 xxljob 启动参数定义到 configmap 中,方便调整。为了通讯安全,注意这里定义了 accessToken,业务使用时也必须定义此 accessToken
- 定义了 xxljob 使用的基础版本(2.4.1),默认开放端口(8080)及资源使用情况(内存 1g,cpu 2)
- 定义了访问 pod 的方式(即 service 通过 ClusterIP 访问,注意,所有 pod 都不对外,只在负载均衡层暴露 gateway)
为了更加高效的访问,对于部署在 k8s 上的 java 服务期望能够以内网的方式进行请求访问注册,那我们在业务使用时可这样设置:http:{服务名}.{命名空间}.svc.cluster.local:{端口},即:http://xxl-job-admin.${spring.profiles.active}.svc.cluster.local:8080
日志采集规则配置
一般来说,日志采集采用多行文本方式,数据源为标准输出,采集规则如下:
\d+-\d+-\d+\s+\d+:\d+:\d+\.\d+\s+.*采集示例:
2024-07-03 22:49:58.911 f07df976729e27b5 f07df976729e27b5 ERROR [reactor-http-epoll-3] c.d.gateway.exception.GatewayExceptionHandler - [网关异常处理]请求路径:/api/auth/login,异常信息
org.apache.dubbo.rpc.RpcException: Failed to invoke the method login in the service com.dayaofang.member.provider.IMemberLoginProvider. Tried 1 times of the providers [172.19.0.254:20880] (1/1) from the registry 172.16.0.6:8848 on the consumer 172.19.0.142 using the dubbo version 2.7.23. Last error is: jwt 解析失败:[object Null]
at org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker.doInvoke(FailoverClusterInvoker.java:110)
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Error has been observed at the following site(s):
*__checkpoint ⇢ org.springframework.web.cors.reactive.CorsWebFilter [DefaultWebFilterChain]
*__checkpoint ⇢ org.springframework.cloud.gateway.filter.WeightCalculatorWebFilter [DefaultWebFilterChain]
*__checkpoint ⇢ cn.dev33.satoken.reactor.filter.SaReactorFilter [DefaultWebFilterChain]
*__checkpoint ⇢ cn.dev33.satoken.reactor.filter.SaPathCheckFilterForReactor [DefaultWebFilterChain]
*__checkpoint ⇢ org.springframework.cloud.sleuth.instrument.web.TraceWebFilter [DefaultWebFilterChain]
*__checkpoint ⇢ org.springframework.boot.actuate.metrics.web.reactive.server.MetricsWebFilter [DefaultWebFilterChain]
*__checkpoint ⇢ HTTP POST "/api/auth/login" [ExceptionHandlingWebHandler]
Original Stack Trace:
at org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker.doInvoke(FailoverClusterInvoker.java:110)
at org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker.invoke(AbstractClusterInvoker.java:265)
at org.apache.dubbo.rpc.cluster.interceptor.ClusterInterceptor.intercept(ClusterInterceptor.java:47)
at org.apache.dubbo.rpc.cluster.support.wrapper.AbstractCluster$InterceptorInvokerNode.invoke(AbstractCluster.java:92)
at org.apache.dubbo.rpc.cluster.support.wrapper.MockClusterInvoker.invoke(MockClusterInvoker.java:98)
at org.apache.dubbo.registry.client.migration.MigrationInvoker.invoke(MigrationInvoker.java:170)
at org.apache.dubbo.rpc.proxy.InvokerInvocationHandler.invoke(InvokerInvocationHandler.java:96)
at org.apache.dubbo.common.bytecode.proxy1.login(proxy1.java)
at com.dayaofang.gateway.handler.AuthLoginHandler.lambda$handle$0(AuthLoginHandler.java:62)
at reactor.core.publisher.MonoFlatMap$FlatMapMain.onNext(MonoFlatMap.java:125)
at reactor.core.publisher.FluxOnErrorResume$ResumeSubscriber.onNext(FluxOnErrorResume.java:79)
at reactor.core.publisher.FluxOnErrorResume$ResumeSubscriber.onNext(FluxOnErrorResume.java:79)
at reactor.core.publisher.Operators$MonoSubscriber.complete(Operators.java:1816)
at reactor.core.publisher.MonoFlatMap$FlatMapMain.onNext(MonoFlatMap.java:151)
at reactor.core.publisher.FluxContextWrite$ContextWriteSubscriber.onNext(FluxContextWrite.java:107)
at reactor.core.publisher.FluxMapFuseable$MapFuseableConditionalSubscriber.onNext(FluxMapFuseable.java:299)
at reactor.core.publisher.FluxFilterFuseable$FilterFuseableConditionalSubscriber.onNext(FluxFilterFuseable.java:337)
at reactor.core.publisher.Operators$MonoSubscriber.complete(Operators.java:1816)
at reactor.core.publisher.MonoCollect$CollectSubscriber.onComplete(MonoCollect.java:160)
at reactor.core.publisher.FluxMap$MapSubscriber.onComplete(FluxMap.java:144)
at reactor.core.publisher.FluxPeek$PeekSubscriber.onComplete(FluxPeek.java:260)
at reactor.core.publisher.FluxMap$MapSubscriber.onComplete(FluxMap.java:144)
at reactor.netty.channel.FluxReceive.onInboundComplete(FluxReceive.java:400)
at reactor.netty.channel.ChannelOperations.onInboundComplete(ChannelOperations.java:419)
at reactor.netty.http.server.HttpServerOperations.onInboundNext(HttpServerOperations.java:603)
at reactor.netty.channel.ChannelOperationsHandler.channelRead(ChannelOperationsHandler.java:113)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:444)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at reactor.netty.http.server.HttpTrafficHandler.channelRead(HttpTrafficHandler.java:266)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:442)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at io.netty.channel.CombinedChannelDuplexHandler$DelegatingChannelHandlerContext.fireChannelRead(CombinedChannelDuplexHandler.java:436)
at io.netty.handler.codec.ByteToMessageDecoder.fireChannelRead(ByteToMessageDecoder.java:336)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:308)
at io.netty.channel.CombinedChannelDuplexHandler.channelRead(CombinedChannelDuplexHandler.java:251)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:442)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:440)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)
at io.netty.channel.epoll.AbstractEpollStreamChannel$EpollStreamUnsafe.epollInReady(AbstractEpollStreamChannel.java:800)
at io.netty.channel.epoll.EpollEventLoop.processReady(EpollEventLoop.java:499)
at io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:397)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.lang.Thread.run(Thread.java:750)
Caused by: cn.dev33.satoken.jwt.exception.SaJwtException: jwt 解析失败:[object Null]
at cn.dev33.satoken.jwt.SaJwtTemplate.parseToken(SaJwtTemplate.java:185)
at cn.dev33.satoken.jwt.SaJwtTemplate.getPayloadsNotCheck(SaJwtTemplate.java:233)
at cn.dev33.satoken.jwt.SaJwtUtil.getPayloadsNotCheck(SaJwtUtil.java:162)
at cn.dev33.satoken.jwt.StpLogicJwtForSimple.getExtra(StpLogicJwtForSimple.java:81)
at cn.dev33.satoken.jwt.StpLogicJwtForSimple.getExtra(StpLogicJwtForSimple.java:73)
at cn.dev33.satoken.stp.StpUtil.getExtra(StpUtil.java:407)
at com.wmeimob.infra.auth.dubbo.filter.SaTokenDubboConsumerFilter.invoke(SaTokenDubboConsumerFilter.java:36)
at org.apache.dubbo.rpc.protocol.FilterNode.invoke(FilterNode.java:61)
at org.apache.dubbo.rpc.protocol.InvokerWrapper.invoke(InvokerWrapper.java:56)
at org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker.doInvoke(FailoverClusterInvoker.java:79)
at org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker.invoke(AbstractClusterInvoker.java:265)
at org.apache.dubbo.rpc.cluster.interceptor.ClusterInterceptor.intercept(ClusterInterceptor.java:47)
at org.apache.dubbo.rpc.cluster.support.wrapper.AbstractCluster$InterceptorInvokerNode.invoke(AbstractCluster.java:92)
at org.apache.dubbo.rpc.cluster.support.wrapper.MockClusterInvoker.invoke(MockClusterInvoker.java:98)
at org.apache.dubbo.registry.client.migration.MigrationInvoker.invoke(MigrationInvoker.java:170)
at org.apache.dubbo.rpc.proxy.InvokerInvocationHandler.invoke(InvokerInvocationHandler.java:96)
at org.apache.dubbo.common.bytecode.proxy1.login(proxy1.java)
at com.dayaofang.gateway.handler.AuthLoginHandler.lambda$handle$0(AuthLoginHandler.java:62)
at reactor.core.publisher.MonoFlatMap$FlatMapMain.onNext(MonoFlatMap.java:125)
at reactor.core.publisher.FluxOnErrorResume$ResumeSubscriber.onNext(FluxOnErrorResume.java:79)
at reactor.core.publisher.FluxOnErrorResume$ResumeSubscriber.onNext(FluxOnErrorResume.java:79)
at reactor.core.publisher.Operators$MonoSubscriber.complete(Operators.java:1816)
at reactor.core.publisher.MonoFlatMap$FlatMapMain.onNext(MonoFlatMap.java:151)
at reactor.core.publisher.FluxContextWrite$ContextWriteSubscriber.onNext(FluxContextWrite.java:107)
at reactor.core.publisher.FluxMapFuseable$MapFuseableConditionalSubscriber.onNext(FluxMapFuseable.java:299)
at reactor.core.publisher.FluxFilterFuseable$FilterFuseableConditionalSubscriber.onNext(FluxFilterFuseable.java:337)
at reactor.core.publisher.Operators$MonoSubscriber.complete(Operators.java:1816)
at reactor.core.publisher.MonoCollect$CollectSubscriber.onComplete(MonoCollect.java:160)
at reactor.core.publisher.FluxMap$MapSubscriber.onComplete(FluxMap.java:144)
at reactor.core.publisher.FluxPeek$PeekSubscriber.onComplete(FluxPeek.java:260)
at reactor.core.publisher.FluxMap$MapSubscriber.onComplete(FluxMap.java:144)
at reactor.netty.channel.FluxReceive.onInboundComplete(FluxReceive.java:400)
at reactor.netty.channel.ChannelOperations.onInboundComplete(ChannelOperations.java:419)
at reactor.netty.http.server.HttpServerOperations.onInboundNext(HttpServerOperations.java:603)
at reactor.netty.channel.ChannelOperationsHandler.channelRead(ChannelOperationsHandler.java:113)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:444)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at reactor.netty.http.server.HttpTrafficHandler.channelRead(HttpTrafficHandler.java:266)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:442)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at io.netty.channel.CombinedChannelDuplexHandler$DelegatingChannelHandlerContext.fireChannelRead(CombinedChannelDuplexHandler.java:436)
at io.netty.handler.codec.ByteToMessageDecoder.fireChannelRead(ByteToMessageDecoder.java:336)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:308)
at io.netty.channel.CombinedChannelDuplexHandler.channelRead(CombinedChannelDuplexHandler.java:251)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:442)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:440)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)
at io.netty.channel.epoll.AbstractEpollStreamChannel$EpollStreamUnsafe.epollInReady(AbstractEpollStreamChannel.java:800)
at io.netty.channel.epoll.EpollEventLoop.processReady(EpollEventLoop.java:499)
at io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:397)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.lang.Thread.run(Thread.java:750)
Caused by: cn.hutool.jwt.JWTException: The token was expected 3 parts, but got 1.
at cn.hutool.jwt.JWT.splitToken(JWT.java:404)
at cn.hutool.jwt.JWT.parse(JWT.java:96)
at cn.hutool.jwt.JWT.<init>(JWT.java:85)
at cn.hutool.jwt.JWT.of(JWT.java:66)
at cn.dev33.satoken.jwt.SaJwtTemplate.parseToken(SaJwtTemplate.java:183)
... 59 common frames omitted使用流水线/命令行来部署
命令行部署
开发人员在本地开发环境中,进行 docker 镜像构建来产生一个新的镜像。然后在云平台手动去点击重新部署来实现。可通过以下脚本来实现:
mvn -Dmaven.test.skip=true clean package -pl gateway -am -P test
-Ddocker.register.url=xxxx
-Djib.skip=false jib:buildjib 是一个 maven 插件。它无需 docker 环境便可构建一个镜像出来。在标品微服务框架中,默认引入此插件。
<plugin>
<groupId>com.google.cloud.tools</groupId>
<artifactId>jib-maven-plugin</artifactId>
<configuration>
<from>
<image>
registry.cn-hangzhou.aliyuncs.com/wmeimob/wmeimob:openjdk-8-jdk-alpine
</image>
</from>
<to>
<image>${docker.register.url}/${project.artifactId}:${project.version}</image>
<tags>
<!--版本号-->
<tag>${project.version}</tag>
</tags>
<auth>
<!--在docker-hub或者阿里云上的账号和密码-->
<username>${docker.register.username}</username>
<password>${docker.register.password}</password>
</auth>
</to>
<allowInsecureRegistries>true</allowInsecureRegistries>
<container>
<!--微服务的启动类-->
<mainClass>${scripts_bootMain}</mainClass>
<!--使用该参数将镜像的创建时间与系统时间对其-->
<creationTime>USE_CURRENT_TIMESTAMP</creationTime>
<entrypoint>
<shell>sh</shell>
<option>-c</option>
<arg>java ${JAVA_OPTS} -cp /app/resources/:/app/classes/:/app/libs/* ${scripts_bootMain}
</arg>
</entrypoint>
<ports>
<!--暴漏的端口号-->
<port>18080</port>
</ports>
</container>
</configuration>
</plugin>为了方便构建,可以将其配置到 idea 中。
先添加 clean 命令,用于确保每次构建不会存在缓存

gateway 添加如下构建命令
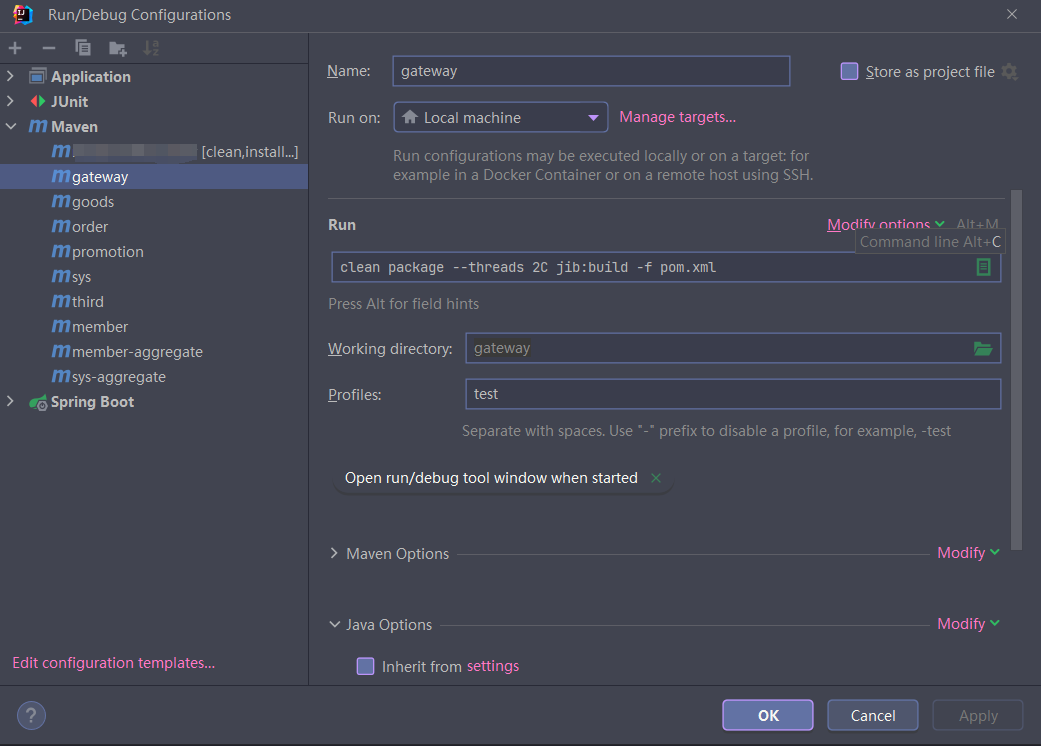
在 VM Options 中添加如下配置:
-Djib.disableUpdateChecks=true
-Ddocker.register.url=xxxx #镜像地址
-Ddocker.register.username=xxx
-Ddocker.register.password=xxxprofiles 为 test 表示当前构建的是 test 环境镜像,如果需要构建 prod,需要调整对应的镜像推送地址
我们可以发现,通过这种方式构建有点“累”。如果本地能直接构建镜像,云平台自动部署那就有点“美好”了。
为了达到此目的。我们可以在容器镜像服务中添加触发器,如图:
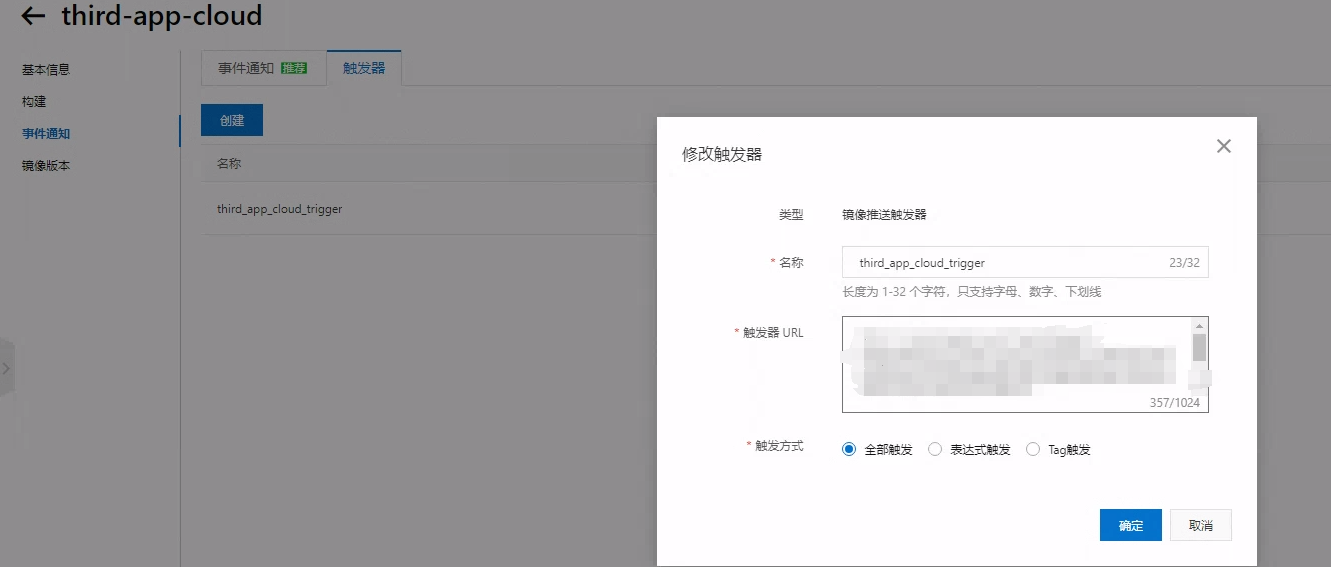
而这个触发器 URL 又从哪里来呢?
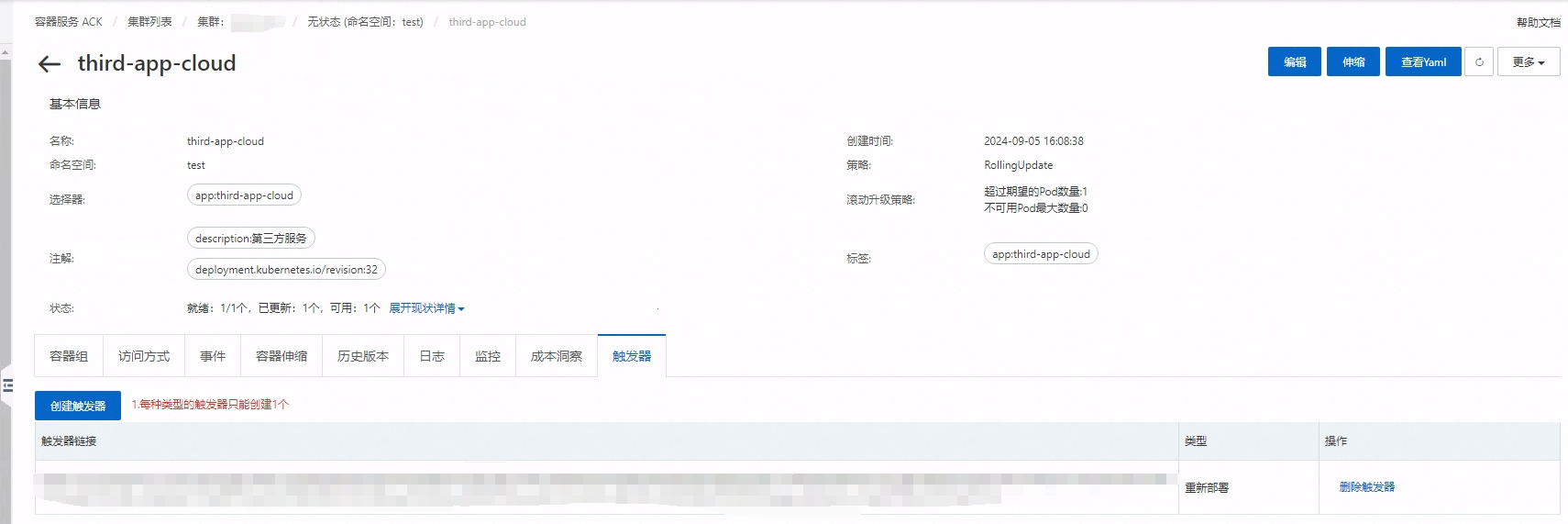
通过新建按钮可以得到此 URL。
那有了这个设置,我们便可以实现本地触发镜像构建,自动进行部署。
看起来是很好了,但是还要本地构建,本地很卡的说!!!
流水线
为了拯救本地的卡,我们可以在云效上使用流水线来实现镜像构建。为了更好的满足多数项目的构建需求,将流水线部署参数进行抽象处理(变量化)
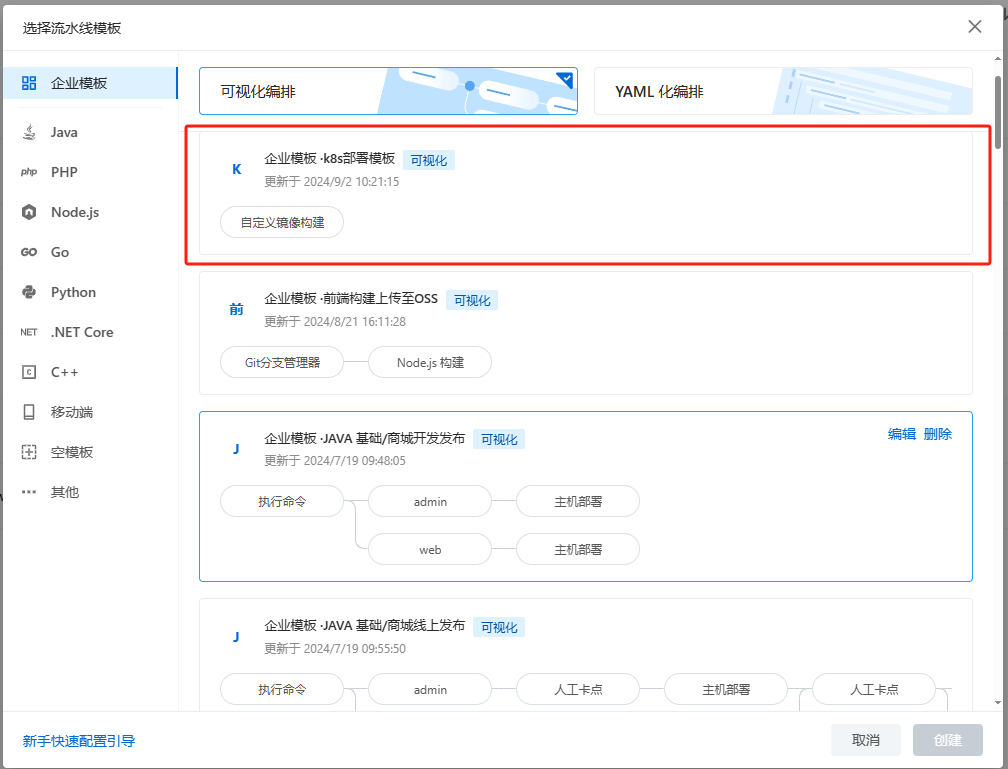
新建流水线时,选择此模板。选择后,进入流水线编辑,调整代码仓库地址及进行变量缓存设置。

docker 变量说明:
docker 账号地址,密码怎么不在这里呢?
- dockerUserName
- dockerImageUrl
docker 密码在哪里呢?这是因为流水线里密码是密文。无法进行变量引用。需要在流水线中填入。
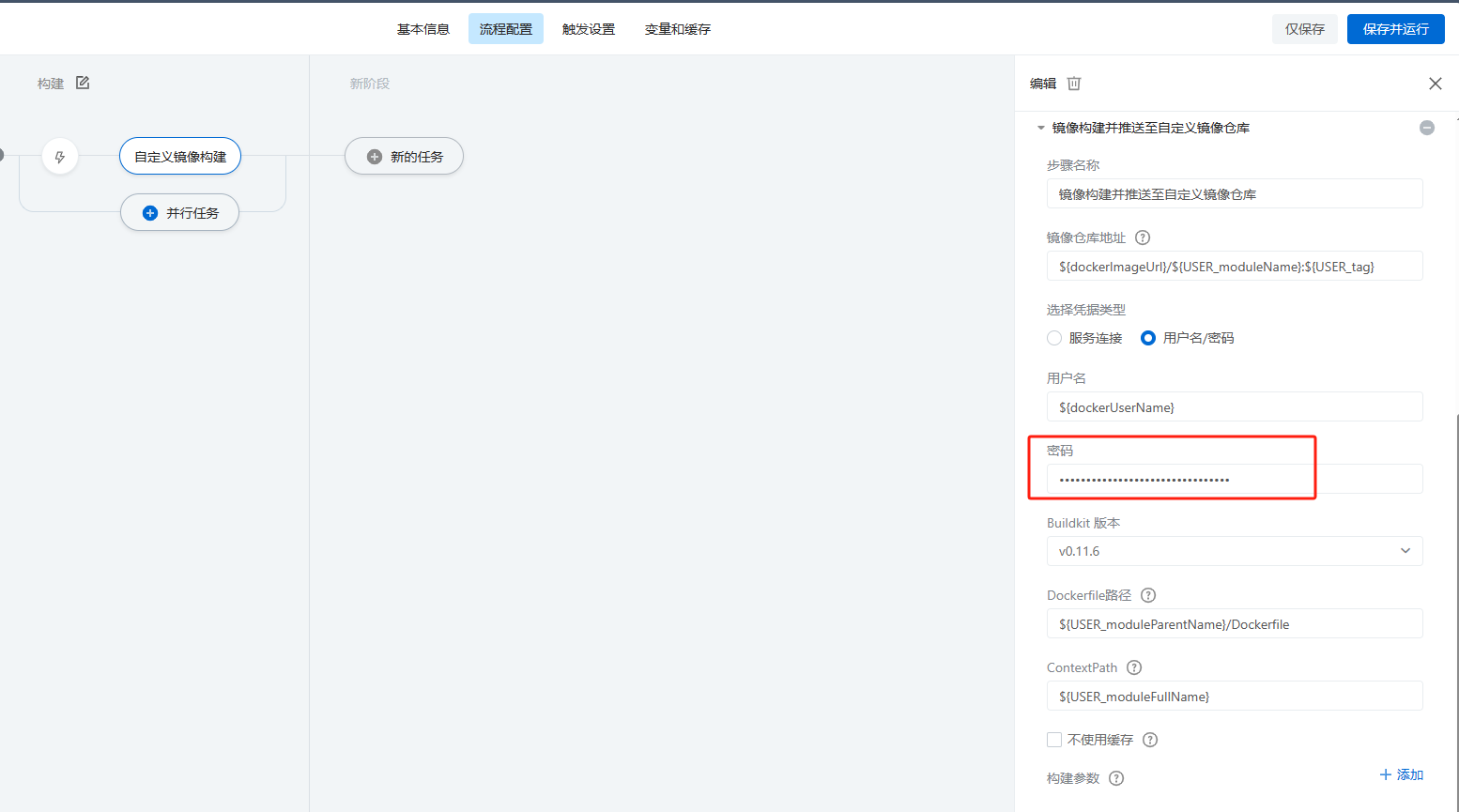
其他变量说明:
- USER_tag 镜像标签,默认 1.0-SNAPSHOT
- USER_env 构建环境
- USER_moduleFullName 模块名称,配置规则是指向模块下的 web 启动目录,配置示例值 gateway,goods/goods-app-cloud,member/member-app-cloud


为什么这么设置呢?这是因为在 maven 构建时,需要指定构建模块,定位 dockerfile 文件时,也需要。
这个方式的部署有一个问题,就是同一个镜像 TAG。也正因为这个原因,腾讯云利用这套机制无法实现自动构建。同一个 TAG 缺点是,无法利用 K8S 回滚机制。
流水线进阶
先来看下现在改进后的流水线
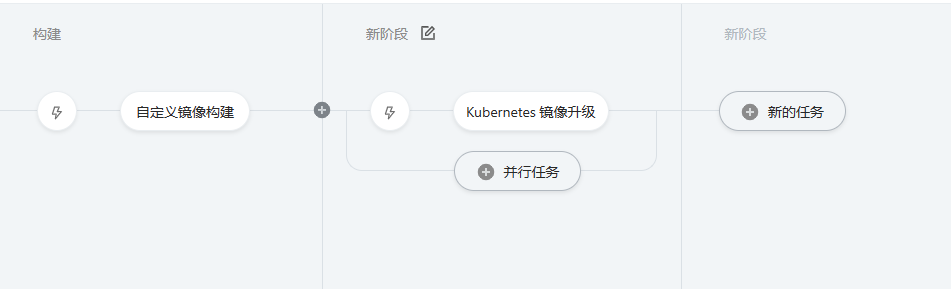
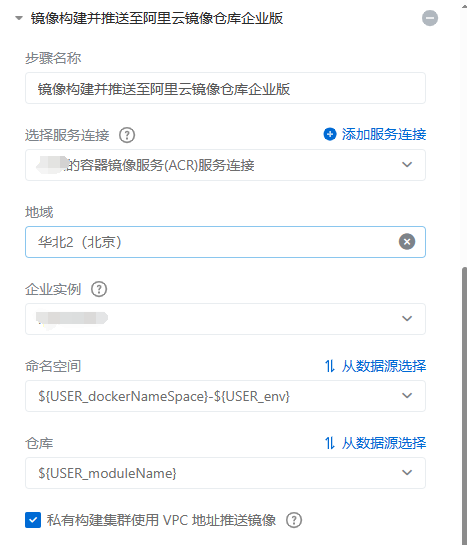
可以看到,比之前多了个镜像升级操作。同时镜像构建也和之前不一样了。由自定义镜像构建改成企业版:
有几点变化:
- 使用服务链接
- 地域无法关联时手动选择
- 企业实例会自动关联
- 命名空间/仓库以变量的方式进行设置
${USER_dockerNameSpace}-${USER_env}${USER_moduleName}
- 同时勾选 vpc 地址推送(这主要是为了实现内网拉取)
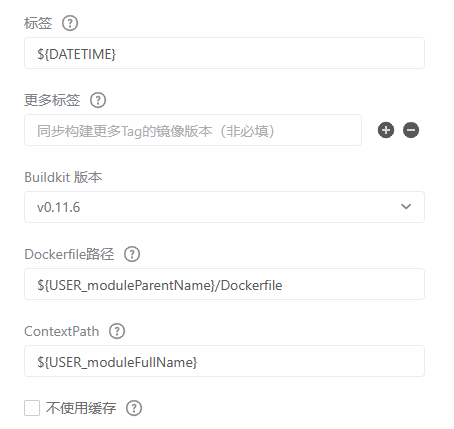
- 镜像标签变量设置
${DATETIME}
- docker Dockerfile路径/上下文设置
${USER_moduleParentName}/Dockerfile${USER_moduleFullName}
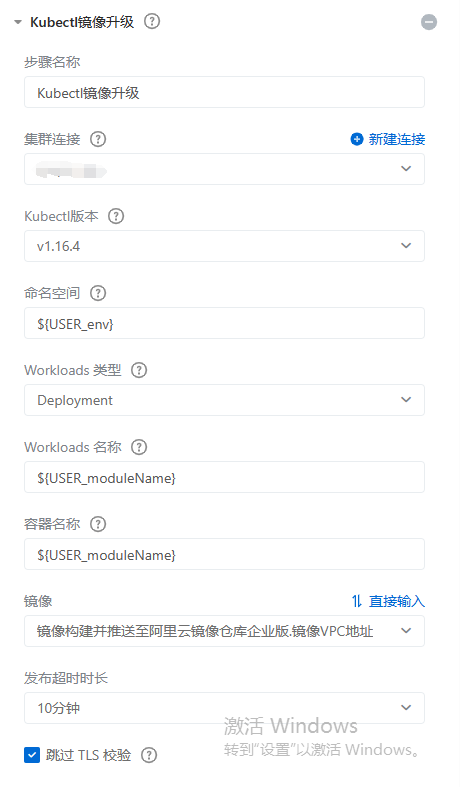
有几点变化:
- 使用集群链接
- Kubectl 版本选择 v1.16.4
- 命名空间变量进行设置
${USER_env}
- Workloads 类型为 Deployment
- Workloads/容器 名称变量进行设置
${USER_moduleName}
最后来看一下涉及到的变量:

最后来看下,服务链接怎么来的?参考这里
通过上面这种方式,便可以达到 k8s 部署最佳的是实践。但流水线每个月有时效要求,如果当月构建数量过多,则没有免费额度。为了避免这种情况发生,可以将流水线部署到客户哪里。
部署到另一个账号上
sources:
repo_0:
type: customGitlab
name: xxx
endpoint: "xxx.git"
branch: dev
certificate:
type: sshKey
defaultWorkspace: repo_0
stages:
stage_0:
name: 构建
jobs:
job_0:
name: 自定义镜像构建
runsOn:
group: public/cn-beijing
labels: linux,amd64
steps:
step_0:
name: 执行命令
step: Command
with:
variables: []
run: |-
echo ${USER_moduleFullName}
echo "USER_moduleParentName=${USER_moduleFullName%/*}
"> .env
step_1:
name: 设置变量
step: SetVariables
with:
value: ${USER_moduleParentName}
key: USER_moduleParentName
step_2:
name: 执行命令
step: Command
with:
variables: []
run: |-
echo ${USER_moduleFullName}
echo "USER_moduleName=${USER_moduleFullName##*/}
"> .env
step_3:
name: 设置变量
step: SetVariables
with:
value: ${USER_moduleName}
key: USER_moduleName
step_4:
name: Java 构建
step: JavaBuild
with:
jdkVersion: '1.8'
mavenVersion: 3.6.3
run: mvn -T 1C clean package -P ${USER_env} -pl ${USER_moduleFullName}
-am -Dmaven.test.skip=true -Dautoconfig.skip
step_5:
name: 镜像构建并推送至阿里云镜像仓库个人版
step: ACRDockerBuild
with:
artifact: artifact
variables: []
dockerfilePath: ${USER_moduleParentName}/Dockerfile
noCache: false
dockerRegistry: registry.cn-beijing.aliyuncs.com/${USER_namespace}-${USER_env}/${USER_moduleName}
useVpcAddress: true
contextPath: ${USER_moduleFullName}
buildkitVersion: v0.11.6
dockerTag: ${DATETIME}
region: cn-beijing
serviceConnection: xxx
driven: auto
plugins: []
stage_1:
name: 新阶段
jobs:
job_1:
name: Kubernetes 镜像升级
runsOn:
group: public/cn-beijing
labels: linux,amd64
steps:
step_0:
name: Kubectl镜像升级
step: KubectlSetImage
with:
container: ${USER_moduleName}
artifact: $[stages.stage_0.job_0.step_5.artifacts.artifact_vpc]
workloadKind: deployment
skipTlsVerify: true
kubernetesCluster: xxx
namespace: ${USER_env}
workload: ${USER_moduleName}
kubectlVersion: 1.16.4
rolloutTimeout: 10
driven: auto
plugins: []sources:
repo_0:
type: customGitlab
name: xxx
endpoint: xxx
branch: dev
certificate:
type: sshKey
defaultWorkspace: repo_0
stages:
stage_0:
name: 构建
jobs:
job_0:
name: Java 构建
runsOn:
group: public/cn-beijing
labels: linux,amd64
steps:
step_0:
name: 执行命令
step: Command
with:
variables: []
run: |-
echo ${USER_moduleFullName}
echo "USER_moduleParentName=${USER_moduleFullName%/*}
"> .env
step_1:
name: 设置变量
step: SetVariables
with:
value: ${USER_moduleParentName}
key: USER_moduleParentName
step_2:
name: 执行命令
step: Command
with:
variables: []
run: |-
echo ${USER_moduleFullName}
echo "USER_moduleName=${USER_moduleFullName##*/}
"> .env
step_3:
name: 设置变量
step: SetVariables
with:
value: ${USER_moduleName}
key: USER_moduleName
step_4:
name: Java 构建
step: JavaBuild
with:
jdkVersion: '1.8'
mavenVersion: 3.5.2
run: mvn -T 1C clean package -P ${USER_env} -pl ${USER_moduleFullName}
-am -Dmaven.test.skip=true -Dautoconfig.skip
step_5:
name: 镜像构建并推送至阿里云镜像仓库企业版
step: ACREEDockerBuild
with:
variables: []
instance: xxx #实例名称
contextPath: ${USER_moduleFullName}
buildkitVersion: v0.11.6
artifact: artifact
dockerfilePath: ${USER_moduleParentName}/Dockerfile
noCache: true
namespace: ${USER_namespace}-${USER_env}
dockerRegistry: ${USER_moduleName}
useVpcAddress: true
dockerTag: ${DATETIME}
region: cn-beijing # 地区,替换成实际的
serviceConnection: xxx #服务链接
driven: auto
plugins: []
stage_1:
name: 部署
jobs:
job_1:
name: Kubernetes 发布
runsOn:
group: public/cn-beijing
labels: linux,amd64
steps:
step_0:
name: Kubectl镜像升级
step: KubectlSetImage
with:
container: ${USER_moduleName}
artifact: $[stages.stage_0.job_0.step_5.artifacts.artifact_vpc]
workloadKind: deployment
skipTlsVerify: false
kubernetesCluster: xxx
namespace: ${USER_env}
workload: ${USER_moduleName}
kubectlVersion: 1.16.4
rolloutTimeout: 10
driven: auto
plugins: []TIP
为了方便迁移,流水线使用 yaml 模板会更加容易构建流水线,其中代码关联选择自建 gitlab -》公钥。将其添加至云效对应代码仓库里的部署密钥中即可。
其中的 $ 变量和可视化模板变量一致。
xxx 为需要替换的变量。
k8s高级特性
- 滚动更新&spring boot 优雅下线
默认情况下,当我们创建一个 pod 时,默认更新方式就已经是滚动更新了。看如下内容:
spec:
replicas: 1
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate待完善
- 节点调度
待完善
- 动态扩缩容
hpa 是应对高并发应用资源不足的一个重要手段。这里以阿里云为例,阿里云上只提供cpu/内存,但这两个指标并不准确。因而我们可以利用 arms 监控的 qps 指标,来达到当 qps 指标达到某个阈值时,动态扩缩容。如果是电商类场景可参考这里配置。
- 证书文件如何配置
例如,我们常见的微信支付证书/密钥文件,通常是在项目中配置其对应的文件路径,但在k8s中我们怎么实现呢?
通过 sercet config 结合数据卷/环境变量来实现。
接下来介绍下 sercet config 如何实现,通过如下命令:
cat 文件名 | base64 -w 0这样会得到一个 base64 字符串。
如果有多个文件,依次进行生成。对于 p12 或其他格式二进制文件需要加上 -w 参数,这表示用于去掉换行符。而对于普通文本文件则不需要这个命令。
而后通过如下命令创建 sercet config:
apiVersion: v1
data:
wx_keyString: p12 证书 base64 字符串
wx_privateCertString: apiclient_cert.pem 证书 base64 字符串
wx_privateKeyString: apiclient_key.pem证书 base64 字符串
kind: Secret
metadata:
name: pay-secret
namespace: test
type: Opaque注意命名空间,依次填入生成的 base64 字符串。其中我们定义了一个名为 pay-secret 的配置项,wx_keyString/wx_privateCertString/wx_privateKeyString 为具体的文件项。
创建好后,在 pod yaml 中进行引用(也可以在控制台通过UI界面创建引用)
这是数据卷的使用:
spec:
template:
spec:
containers:
volumeMounts:
- mountPath: /app/cert #容器路径,配置中心使用此路径+文件项来引用
name: pay-secret-volume #数据卷名称
spec:
template:
spec:
volumes:
- name: pay-secret-volume
secret: #数据卷类型为 sercet config (保密字典)
defaultMode: 420
secretName: pay-secret #sercet config (保密字典)名称这是环境变量的使用:
containers:
- env:
- name: wmeimob.wx.pay.keyString
valueFrom:
secretKeyRef:
key: wx_keyString
name: pay-secret
- name: wmeimob.wx.pay.privateCertString
valueFrom:
secretKeyRef:
key: wx_privateCertString
name: pay-secret
- name: wmeimob.wx.pay.privateKeyString
valueFrom:
secretKeyRef:
key: wx_privateKeyString
name: pay-secret如果需要数据卷读取,程序中通过以下路径可以读取到配置:
/app/cert/wx_keyString
/app/cert/wx_privateKeyString
/app/cert/wx_privateCertString- 静态地址配置
腾讯云(阿里云有报错则也需要)需要先检查如下设置项:
找到 xxx-ingress-nginx-controller configmap,将 allow-snippet-annotations: 调成 "true"
而后在 ingress yaml 中,添加如下内容:
nginx.ingress.kubernetes.io/server-snippet: |
location /WW_verify_xxx.txt { default_type text/plain; return 200 "xxx"; }- 开启 gzip
找到 xxx-ingress-nginx-controller configmap,设置 use-gzip 为 “true”,华为云需要在插件中心找到 nginx ,点击编辑修改
而后在 ingress yaml 中,添加如下内容:
nginx.ingress.kubernetes.io/server-snippet: gzip on;注意,华为云、阿里云不需要加
- 静态资源缓存
在 ingress yaml 中,添加如下内容:
nginx.ingress.kubernetes.io/configuration-snippet: >
more_set_headers "cache-Control: no-cache, no-store"; if ($request_uri ~*
\.(?:ico|css|js|gif|jpg|jpeg|png|svg|woff2|woff|ttf|eo|mp3|glb)($|\?.*)) {
more_set_headers "cache-control: public, max-age=2592000";
}根据需要调整正则以及缓存时间
- jvm 参数配置到 configmap 中
configmap 相当于 nacos。好处是配置与业务分离,便于调整。参考一键生成configmap一节。
- ssl 证书配置
ssl 证书有三种配置方式。泛域名证书只支持 xxx.xxx.com 形式域名,点此详细了解
ingress tls
spec:
tls:
- hosts:
- www.xxx.com
secretName: xxx在已有的 ingress 中添加对应的域名,以及新增对应的 secret 字典。这个步骤可在云平台 UI 控制台进行添加。
负载均衡
- 阿里云
进入负载均衡,找到证书管理,进行添加。这个步骤直接在云平台进行操作。
而后,在 ack 集群,服务菜单找到命名空间“kube-system”下的 nginx-ingress-lb,增加如下配置:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-cert-id: xxxx # xxx 为添加证书完后在列表上可看到
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-protocol-port: 'https:443,http:80'
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-forward-port: '80:443'增加完后理论上就可以了。但是去访问会报 400 bad request 错误。这时候需要在修改下:
spec:
ports:
- name: http
nodePort: 31893
port: 80
protocol: TCP
targetPort: 80
- name: https
nodePort: 31400
port: 443
protocol: TCP
targetPort: 443
targetPort: 80- 腾讯云
暂无。
waf 防火墙
根据云上 UI 控制台进行添加即可。
常见错误
- 容器内使用 arthas 报 Unable to get pid of LinuxThreads manager thread 错误
解决方法:
RUN echo "java -jar \${JAVA_OPTS} app.jar" > start.sh \
&& chmod 777 start.sh
ENTRYPOINT ./start.sh- PreStopHook failed
解决方法:
这是容器停止前执行的一个回调函数,是容器优雅关闭的一个机制。 会出现这个错误,说明容器状态为 Terminating 且持续很久并超过terminationGracePeriodSeconds所定义的阈值还没有优雅退出,最后被强制终结导致的。 因此建议去掉 preStop 的定义,由程序实现优雅退出。
- 探针类 context deadline exceeded (Client.Timeout exceeded while awaiting headers) dial tcp xxx:xx: connect: connection refused 错误
解决方法:
通常我们为了配合优雅关闭,会定义启动/存活/就绪等探针。而出现这个错误,说明initialDelaySeconds阈值的设定过小,而且探针有个机制,当超时时间配置为1s时, 探针探测连续三次1s ,1s内服务没响应就报错。因此,这里需要观察一下业务正常启动时间是多少,然后调整对应的initialDelaySeconds参数。而探针比较合理的配置参照 deployment 设置。